



Die Entwicklung von Software ist zu gleichen Teilen Wissenschaft und Kunst. GHGA ist da keine Ausnahme, auch wir müssen ein kreatives Gleichgewicht zwischen vielen Aspekten und Anforderungen finden:
Einerseits möchten wir die best mögliche Version unseres Genomarchivs entwickeln. Andererseits ist GHGA ein langfristiges Projekt, so dass die Möglichkeit zur Wartung und Erweiterung ein wichtiger Aspekt ist. Unsere Softwarelösungen sollten einfach umzusetzen sein, um die Anbindung neuer Datenknoten an unser Netz zu ermöglichen. Gleichzeitig müssen wir die nötige Flexibilität bieten, um uns an die lokal verfügbaren Ressourcen und Infrastrukturen anzupassen. Außerdem sollen die von uns entwickelten Produkte nicht nur von uns selbst genutzt werden, sondern wir möchten auch der breiteren nationalen und internationalen Forschungs- und Gesundheitsgemeinschaft dienen.
Alles beginnt mit der richtigen Kultur in der Softwareentwicklung. Die kontinuierliche Optimierung unserer agilen Entwicklungsprozesse geht dabei Hand in Hand mit DevOps (Entwicklung und Betriebs)-Praktiken. Aus diesem Grund stimmen wir unsere Aktivitäten eng mit der Arbeitsgruppe 'Betrieb der Datenknoten' ab. Ein weiterer wichtiger Aspekt bei der Bewältigung der oben genannten Herausforderungen ist die Wahl fortschrittlicher und dennoch robuster Architekturmuster. Aus diesem Grund implementieren wir, vom ersten Tag an, eine Domänen-gesteuerte Microservice-Architektur. Diese ist nicht nur einfach zu pflegen, sondern erleichtert auch Umstrukturierungen, die im Laufe des Projektes notwendig werden können. Um unabhängig von einem bestimmten Cloud-Anbieter zu sein und einen reibungslosen kontinuierlichen Einsatz zu ermöglichen, setzen wir außerdem auf das Container Verwaltungssystem Kubernetes und sein Ökosystem. Schließlich bemühen wir uns sehr um die Anlehnung an nationale und internationale Software-Standards und wollen deren Entwicklung aktiv vorantreiben, indem wir uns an den Bemühungen der NFDI, ELIXIR Europe, und der GA4GH beteiligen.
Produkte und Erfolge
Der föderale Charakter von GHGA erfordert Fachwissen vor Ort, wenn es um die Vorgänge auf Produktionsebene geht. Diese Tätigkeiten sind in zwei Hauptbereiche unterteilt: (1) Data Stewardship (Datenverwaltung) und (2) DevOps-Vorgänge (Entwicklung und Betrieb). Die GHGA-Produktionsarbeit erfordert eine enge Zusammenarbeit dieser beiden Gruppen für die Durchführung der täglichen GHGA-Aktivitäten.
Data Stewardship (Datenverwaltung). Einer der Schwerpunkte an dem die Arbeitsgruppe arbeitet sind die Details der Helpdesk-Struktur und -Arbeitsweise. Die Data Stewards an den einzelnen Datenzentren bilden das GHGA-Helpdesk-Team und unterstützen die Nutzer bei der Datenübermittlung und bei Anfragen zum Datenzugriff. Die enge Zusammenarbeit mit den Sequenzierzentren gewährleistet eine direkte Verbindung zu den wichtigsten Datenlieferanten von GHGA.
DevOps (Entwicklung und Betrieb). In der ersten Phase von GHGA werden die DevOps-Vorgänge zusammen mit der Software & Infrastruktur Arbeitsgruppe (siehe unten) durchgeführt. Auf diese Weise wird die Bereitstellungs- und Betriebsstrategie eng mit der Softwareentwicklung abgestimmt.
Alle Prozesse innerhalb des Datenknoten-Betriebsteams werden anhand von Standardarbeitsanweisungen (SOPs) organisiert, die ein wesentliches Instrument sind, um sicherzustellen, dass die Datenknoten einzeln und gemeinsam auf reproduzierbare und sichere Weise arbeiten.
Das ELSI (Ethische, Legale und Soziale Aspekte)-Team besteht aus Rechtswissenschaftlern und Ethikforschern. In enger Zusammenarbeit entstehen so die Grundlagen für den ethischen und rechtlichen Kontext von GHGA. Gemeinsam stellen wir die notwendigen ethischen und rechtlichen Dokumente für GHGA bereit (z. B. Einverständniserklärungen, Strategiepapiere und Richtliniendokumente). Damit wollen wir die rechtliche Umsetzung und Interoperabilität von GHGA sicherstellen. Des Weiteren erkundet die Arbeitsgruppe Strategien zur Einbeziehung von Patienten und Betroffenen in die Konzeption und Steuerung von GHGA, um eine breite und dauerhafte gesellschaftliche Unterstützung für das Projekt zu erreichen.
Das Ethik-Team arbeitet an Materialien für Einwilligungserklärungen, die es Datenproduzenten ermöglichen sollen, ihre Daten künftig über GHGA zu teilen. Zusätzlich wird ein Leitfaden erstellt, mit dem bereits vorhandene Einwilligungsformulare mittels neuer Module für die Zwecke von GHGA erweitert werden können. In Zusammenarbeit mit Patientenvertretern werden Informationsressourcen für Patienten entwickelt und Beiträge zu ethischen und rechtlichen Fragen gesammelt. Das Ergebnis wird ein Richtlinienvorschlag (white paper) sein, in dem beschrieben wird, wie Patienten in die GHGA-Projektführung einbezogen werden können, um so das Vertrauen der Beteiligten aufzubauen und zu erhalten.
Das Rechts-Team konzentriert sich auf die Rechtsgrundlagen für die Datenverarbeitung und die bereits erteilten Einwilligungen. Wir arbeiten auch an Risikobewertungen, De-Identifizierungs- und Anonymisierungsmethoden und einem möglichen Verhaltenskodex, um den Projektführungsrahmen für GHGA umzusetzen und die rechtliche Interoperabilität für die Datenverarbeitung innerhalb der EU und in internationalen Datenräumen zu verbessern.
Produkte and Erfolge:
GHGA ist in ein Netzwerk nationaler und internationaler Initiativen wie GDI, fEGA und genomDE eingebettet. Wir sind daher bestrebt, Lösungen für den sicheren Austausch von humanen Omics-Daten im Einklang mit diesen Initiativen zu entwickeln.
Unsere GDI-Arbeitsgruppe widmet sich der Anpassung an die Europäische Genomdateninfrastruktur (GDI) - ein Schlüsselprojekt im Rahmen von GHGAs Bemühungen zur Interoperabilität. Die GDI-Initiative zielt darauf ab, ein grenzüberschreitendes, miteinander verbundenes Netzwerk nationaler Genom-Sammlungen zu schaffen. Damit soll das Ziel der 1+ Million Genome (1+MG) Initiative erreicht werden. Als deutscher Knotenpunkt innerhalb von GDI stellt unsere GDI-Arbeitsgruppe sicher, dass die von GHGA entwickelte Infrastruktur mit den GDI-Knotenpunkten in ganz Europa kompatibel ist.
Im Rahmen der GDI-Arbeitsgruppe konzentrieren wir uns auf die Angleichung von technischen und Metadaten-Aspekten. Auf der technischen Seite integrieren wir das Starter Kit von GDI mit unseren bestehenden GHGA-Diensten. Das Starter Kit bietet wichtige Dienste wie Datenfindung, Zugriffsmanagement, sichere Speicherung und Verarbeitung. Dazu verknüpfen wir unser Datenzugriffsmanagement und die sichere Speicherung mit den Datenfindungs- und -verarbeitungsdiensten von GDI. Derzeit prüfen wir die Verwendung von Beacon v2 für die Datensuche in GHGA. Im Bereich der Metadaten gewährleisten wir den Anschluss an das zentralisierte Benutzerportal von GDI, das Metadaten aus den verschiedenen Knotenpunkten für die Datensatzsuche zusammenfasst.
Produkte und Erfolge
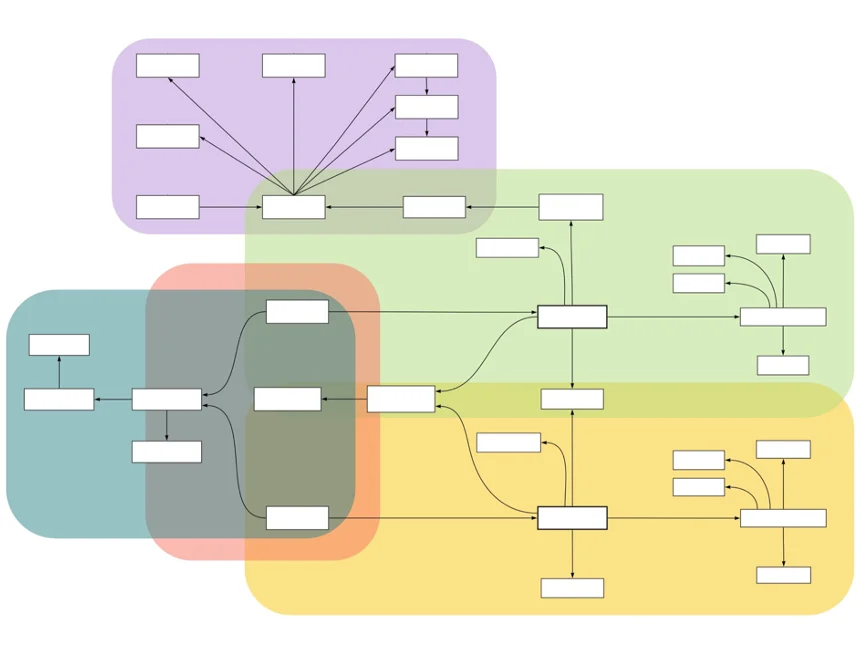
Die Metadaten-Arbeitsgruppe liefert das Modell für die in GHGA gespeicherten Daten und ist eine gemeinsame Anstrengung der konzeptionellen und technischen Abteilungen von GHGA. Das Team bringt Expert:innen mit umfangreichen Kenntnissen aus verschiedenen Bereichen zusammen, die in die Definition des GHGA-Metadatenschemas einfließen, das als Rahmen für das GHGA Metadatenmodell dient.
Ausgangspunkt der Arbeitsgruppe war die Evaluierung bereits bestehender und gut etablierter Metadatenmodelle, wobei der Schwerpunkt auf dem European Genome-phenome Archive (EGA) sowie den Bereichen Krebs und Seltene Erkrankungen lag. Mit dem Vorwissen aus verschiedenen Portalen wurde ein Prototyp erstellt und in mehreren Feedback- und Testrunden verfeinert. Das GHGA-Metadatenschema ist auf GitHub offen zugänglich.
Unser Ziel ist, die GHGA-Metadaten FAIR zu machen, indem wir etablierte und weit verbreitete Ontologien und Vokabulare verwenden, die unseren unterschiedlichen Fachgemeinschaften bei der Beschreibung ihrer Daten sowie bei der Suche nach Daten helfen. Alle Ontologien und Vokabulare werden auf der Grundlage ihrer Wartung und ihres Inhaltsreichtums mit Hilfe von https://fairsharing.org bewertet. Die ermittelten Metadaten, Ontologien und Vokabulare wurden in unserem Metadatenschema strukturiert, das technisch mit Hilfe der Linked Data Modelling Language umgesetzt wurde. LinkML hilft uns dabei, das Metadatenschema an einer Stelle zu erstellen und auch zu aktualisieren, und stellt dem technischen Bereich von GHGA Definitionen des Schemas in verschiedenen Modellierungssprachen, wie JSON und RDF, zur Verfügung.
Erfolge & Produkte

Datenwissenschaftler, Forschende der Biomedizin und Ärzt:innen aus über 20 Institutionen arbeiten bei GHGA zusammen, um dieses ambitionierte Projekt in die Praxis umzusetzen. Sie bilden ein interdisziplinäres Team aus über 80 Mitgliedern, die sich in sehr unterschiedlichen Arbeitsbereichen von GHGA engagieren.
Um einen zielgerichteten Arbeitsablauf zu gewährleisten, unterstützt das Projektmanagement Team die Mitarbeitenden aller anderen Arbeitsgruppen, wo immer es möglich ist. Das beinhaltet gruppenübergreifende administrative Aufgaben, wie z.B. Finanzangelegenheiten und Personaleinstellung. Zusätzlich unterstützt das Projektmanagement die Arbeitsbereiche bei organisatorischen Angelegenheiten (z.B bei der Berichterstattung), bei der Entwicklung von gesetzlichen Rahmenbedingungen, wie auch bei der Organisation von internen und externen Meetings. Des Weiteren ist das Projektmanagement Team in die Projektsteuerung eingebunden und organisiert regelmäßige Treffen mit dem Direktorium und der Wissenschaftlichen Steuerungsgruppe.
An der Schnittstelle zwischen dem GHGA Konsortium und der NFDI, bringt sich das Projektmanagement Team auch auf unterschiedlichen Ebenen in die Arbeit diverser NFDI Gremien ein
Erfolge & Produkte

GHGA nutzt eine Vielzahl von Kommunikationskanälen. So erreichen wir unterschiedliche Zielgruppen mit der gleichen Botschaft: Wenn wir die richtigen Sicherheitsmaßnahmen treffen (worauf wir bei GHGA großen Wert legen), ist das Teilen von Daten sicher und entscheidend für den Fortschritt in der Wissenschaft.
Die Entwicklung der GHGA Infrastruktur ist sowohl auf die Bedürfnisse der Forschungsgemeinschaft abgestimmt, als auch auf die der Ärzt*innen und Forschenden an Kliniken. GHGA steht dafür in engem Kontakt mit den Nutzer*innen und Herstellern von Omics-Daten, die oftmals an Kliniken generiert werden. Nur wenn wir wissen, was Forschende unterschiedlicher Disziplinen brauchen, können wir eine Plattform bereitstellen, die allen Anforderungen genügt.
Mit Vorträgen auf Konferenzen und Workshops wollen wir nicht nur für GHGA werben, sondern auch die Grundsätze des FAIRen Datenaustauschs fördern. Die FAIRe Datennutzung bedarf Kollaboration. Kollaboration zwischen Wissenschaftler*innen und Kliniker*innen. Aber auch zwischen verschiedenen Initiativen, um sicherzustellen, dass nationale und internationale Bemühungen aufeinander abgestimmt sind und idealerweise ähnlichen Standards folgen. Ziel unserer Kommunikationsstrategie ist es, die Genomforschung in deutschen Einrichtungen zu vernetzen.
GHGA liegt der Austausch mit der Öffentlichkeit am Herzen. Wir wollen das Verständnis für und Vertrauen in die Forschung erhöhen und damit letztlich fundierte Entscheidungen über die gemeinsame Nutzung von Daten ermöglichen. Genomforschung kann lebensrettend sein, ist interessant und betrifft uns alle. Daher suchen wir den Dialog mit der Öffentlichkeit, unter anderem durch lokale Veranstaltungen oder unseren Podcast „Der Code des Lebens“!
Erfolge & Produkte
Dem Training-Team liegt es am Herzen, unsere Nutzer:innen und alle Interessierten bei allen Themen zu unterstützen, die für die gemeinsame Nutzung von Daten im Bereich der biomedizinischen Forschung und der Gesundheitsfürsorge sowie der damit verbundenen bioinformatischen Methoden relevant sind. Daher haben wir es uns zur Aufgabe gemacht, Schulungs- und Lernmöglichkeiten in diesen Bereichen anzubieten.
Unser Material reicht von ELSI-Themen wie Einwilligungen und Tools für Einwilligungserklärungen über technische Themen rund um Metadaten, bioinformatische Analyse von DNA und RNA bis hin zu guter Praxis bei Studiendesign und statistischer Analyse. Gemeinsam mit dem GHGA-Outreach-Team wollen wir unsere Nutzer:innen - und ein interessiertes Publikum - auch über Themen informieren, die uns am Herzen liegen, z.B. FAIR Data Sharing und allgemeines Forschungsdatenmanagement, indem wir Kurse und zusätzliches Material zu diesen interessanten Themen anbieten.
Ein wichtiger Teil der Aufgabe von GHGA ist die Erleichterung der gemeinsamen Nutzung von Genomdaten (und anderen Omics-Daten) von verschiedenen Datenerzeuger:innen. Um dies zu ermöglichen, müssen die Daten in das GHGA-Datenportal hochgeladen werden. Sobald die Daten dort sicher gespeichert sind, können sie durchsucht, heruntergeladen (nach erfolgreicher Beantragung einer Genehmigung) und mit zunehmender Funktionalität der GHGA-Dienste sogar mit Hilfe spezieller bioinformatischer Workflows, die von GHGA und der Gemeinschaft entwickelt wurden, analysiert werden.
Der Prozess des Hochladens von Daten in einen Portal kann entmutigend sein, da er die Vorbereitung der Daten vor der Einreichung, das Hochladen der begleitenden Metadaten und das Wissen, wie die Daten technisch hochgeladen werden, umfasst. Auch das Durchsuchen der hochgeladenen Daten, das Auffinden der richtigen Datensätze für die eigene Analyse und die anschließende Beantragung der Genehmigung zum Herunterladen können durch die Anleitung der Macher:innen der Plattform erleichtert werden.
Dieses Nutzererlebnis so reibungslos wie möglich zu gestalten, ist eines der Hauptziele des GHGA Training-Teams. Daher werden wir Schulungsmaterial zur Verfügung stellen, das die Navigation durch alle Aspekte des Datenportals erläutert. In späteren Entwicklungsstadien - wenn Workflows für die Datenanalyse und andere Ressourcen hinzugefügt wurden - werden wir auch hierfür Schulungs- und Unterstützungsmaterial bereitstellen. Die Schulungen werden in verschiedenen Varianten angeboten: Sie können zwischen Live-Webinaren, Video-Tutorials auf Abruf oder textbasierten Materialien wählen - je nachdem, was Ihnen am besten gefällt.
Achievements & Products
Course FAIR in (biological) practice: https://www.youtube.com/playlist?list=PLXMwmQxyLByV8wQ4i9NwG_cDaJGc5Nrhj
Webinare:
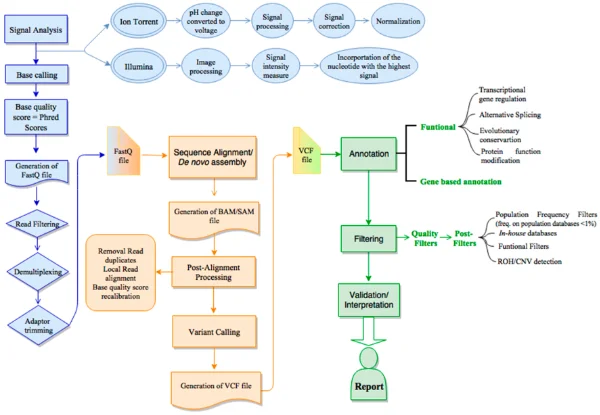
Standardisierte NGS-Workflows bei GHGA
Im GHGA-Workflow-Workstream steht die Standardisierung und Harmonisierung von Analyseabläufen (Workflows) für Next Generation Sequencing (NGS) im Mittelpunkt. Ziel ist es, einen qualitativ hochwertigen und FAIR-konformen Datenaustausch innerhalb der deutschen Life-Science-Forschungsgemeinschaft zu fördern. Statt neue Workflows von Grund auf zu entwickeln, bauen wir auf bestehenden, von der Community etablierten Lösungen auf. Diese werden weiterentwickelt und verbessert, in enger Anlehnung an bewährte Standards wie GA4GH , nf-core und Snakemake.
Der Fokus liegt auf der einheitlichen Verarbeitung von Sequenzier-Rohdaten zu reproduzierbaren, gebrauchsfertigen Forschungsergebnissen, um die Konsistenz und Vergleichbarkeit aller eingereichten Datensätze sicherzustellen.
Zuverlässige Querschnittsanalysen ermöglichen
Standardisierte Workflows sind entscheidend für zuverlässige Querschnittsanalysen. Um dies zu unterstützen, plant GHGA die Einführung automatisierter Qualitätskontroll-(QC-)Pipelines für alle in das GHGA-Archiv eingereichten Daten. Nach der Implementierung werden diese Pipelines Qualitätsberichte erzeugen, die über das GHGA-Datenportal zugänglich sein werden. Diese Berichte ermöglichen es den Nutzern, Datensätze anhand qualitätsbezogener Kriterien zu filtern und gezielt für ihre spezifischen Forschungsfragen auszuwählen.
Sicherstellung von Qualität und Reproduzierbarkeit
Datenqualität und Reproduzierbarkeit stehen im Zentrum unserer Workflow-Strategie. Jede Pipeline durchläuft umfassende Tests im Rahmen kontinuierlicher Integration und Bereitstellung (CI/CD), um ihre technische Stabilität sicherzustellen. Zusätzlich bewerten wir die biologische Leistung mithilfe synthetischer und experimenteller Datensätze wie Seracare-Proben, CHM-Zelllinien und Genome in a Bottle(GiaB).
Bei der Entwicklung einsatzfähiger und skalierbarer Pipelines optimieren wir Ressourcennutzung und Rechenaufwand auf Grundlage von Provenance- und Trace-Daten. Dabei blicken wir insbesondere auf die effiziente Verarbeitung großer Datenmengen.
Unterstützung eines FAIR Data Ecosystems
Unsere Arbeit geht über die Entwicklung von Analysepipelines hinaus. Wir engagieren uns aktiv für den Aufbau eines robusten FAIR-Daten-Ökosystems – durch folgende Maßnahmen:
Alle GHGA-Workflows sind Open Source und auf Community-Plattformen registriert. Sie sind damit auffindbar, zugänglich, interoperabel und wiederverwendbar – zentrale Prinzipien, die den Wandel von GHGA zu einem vollständig integrierten, nationalen Datendienstleister vorantreiben.
Hier finden sie weitere Informationen über unsere von der Gemeinschaft betriebenen Projekte und Analysepipelines.